分组健康状态
分组健康状态用于判断调用异常是单个请求问题,还是某个套餐、模型、上游分组或团队成员的集中问题。企业和团队管理员可以用它快速回答三个问题:
- 哪个分组在指定时间范围内成功率下降
- 哪个用户或令牌贡献了主要请求量、消耗或错误
- 错误是集中在单个 Token,还是已经影响整个分组
排查接口异常时,先看分组健康状态,再进入单条使用日志定位具体 request_id。
数据口径
本页嵌入的公开 status 页面查询的是所选时间段内 aicentos 整个平台所有用户正在使用的分组健康状态,反映全平台分组可用性,具备实时性、公正性和稳定性。
控制台内的 使用日志 → 分组健康状态 按当前账号权限统计可见数据。个人用户通常只看到自己的 Token;企业和团队管理员可结合用户、用户名、令牌和分组维度查看团队使用情况。
如果上方状态页未正常加载,可直接打开 aicentos 分组健康状态。
控制台入口:控制台 → 使用日志。在错误日志或统计视图中,按时间范围、模型、Token、分组、错误消息和状态码筛选。
控制台示例
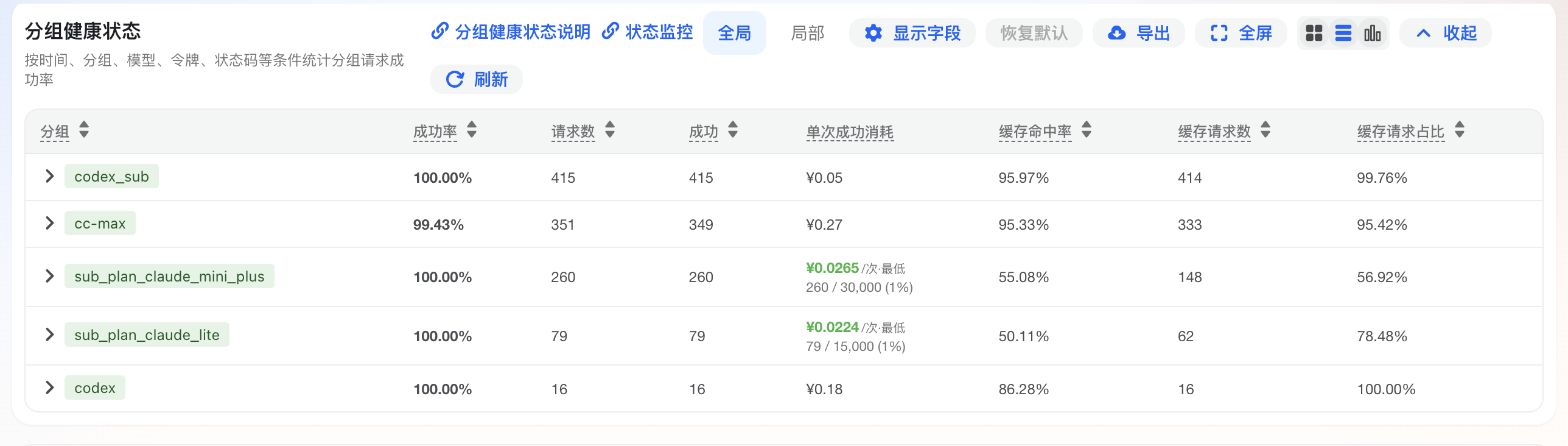
下面是控制台 使用日志 → 分组健康状态 的示例截图,展示分组的成功率、请求数、消耗、缓存命中、平均耗时、最近请求时间和失败原因。
使用原则
先判断影响范围,再处理单条错误。单条日志适合定位具体请求,分组健康状态适合判断问题是否集中发生。
需要解释单条错误消息时,请查看 错误日志说明。
列表展示字段
控制台列表和 CSV 导出的展示列保持一致。列表同时展示两类行:
- 分组行:汇总一个分组在当前时间范围内的整体健康状态。
- 令牌行:展示某个分组下的用户和令牌明细,便于企业、团队管理员定位成员、项目或服务。
| 展示字段 | 适用行 | 字段说明 | 使用建议 |
|---|---|---|---|
| 类型 | 分组行、令牌行 | 标识当前行是 分组 汇总,还是 令牌 明细 | 先看分组行判断整体状态,再看令牌行定位具体成员或 Token |
| 分组 | 分组行、令牌行 | 当前时间段内出现过的分组,包含按量分组、套餐分组、默认分组或特定模型分组 | 判断问题是否集中在某个套餐、模型或上游资源池 |
| 用户ID | 令牌行 | 使用该令牌的用户 ID | 企业排查时用于定位成员账号 |
| 用户名 | 令牌行 | 使用该令牌的用户名 | 用于团队报表、成员沟通和权限核对 |
| 令牌 | 令牌行 | 控制台中配置的 Token 名称 | 判断异常是否只集中在某个 Token |
| 成功率 | 分组行、令牌行 | 成功率 = 成功次数 / 总请求数 | 低于 80% 建议关注;明显低于同组其他行时,优先排查该分组或令牌 |
| 请求数 | 分组行、令牌行 | 当前时间范围内的总请求数 | 样本量太小时不要过度解读成功率 |
| 成功 | 分组行、令牌行 | 返回 2xx 的成功请求次数 | 与“请求数”“错误”一起判断整体可用性 |
| 错误 | 分组行、令牌行 | 返回错误(4xx/5xx)的请求次数 | 错误数升高时,优先查看“失败原因”和错误日志 |
| 消耗 | 分组行、令牌行 | 当前时间段累计的额度消耗,导出时按金额展示 | 用于团队成本核算、项目分摊和异常消耗识别 |
| 缓存命中率 | 分组行、令牌行 | 缓存命中率 = 命中缓存的 Token / 总 Token | 越高越省钱;命中部分通常按低价或免费计算 |
| 缓存Tokens | 分组行、令牌行 | 当前时间段命中缓存的 Token 数 | 这部分通常按低折扣计价,越多越省 |
| 缓存请求数 | 分组行、令牌行 | 至少命中一次缓存的请求次数 | 衡量有多少请求实际用到了缓存 |
| 缓存请求占比 | 分组行、令牌行 | 缓存请求占比 = 命中缓存的请求 / 总请求 | 越高代表越多调用享受到了缓存优惠 |
| 平均缓存Tokens | 分组行、令牌行 | 平均每次命中缓存的 Token 数 | 用于比较不同成员、服务或分组的缓存利用效率 |
| 平均耗时 | 分组行、令牌行 | 平均每次请求耗时,单位为秒 | 越低代表上游响应越快;耗时升高时排查长上下文、长输出和工具链路 |
| 开始时间 | 分组行、令牌行 | 当前时段内该分组或令牌首次出现的时间 | 定位问题或调用开始时间 |
| 最后请求 | 分组行、令牌行 | 当前时段内该分组或令牌最近一次出现的时间 | 判断问题或调用是否仍在持续 |
| 失败原因 | 分组行 | 出现频率最高的几条失败原因,包含状态码和次数;无错误时为空或 - | 优先处理次数最多的错误,不要只看最后一条日志 |
字段来源
展示字段由后台统计数据聚合生成。日常使用以控制台列表和 CSV 导出列为准;只有对接接口或技术排查时,才需要再对照底层字段名。
团队定位
先看分组行判断是否是资源池问题,再看令牌行判断是否由某个用户或令牌造成。如果分组成功率正常但单个令牌错误率高,通常优先排查该成员的 Token、模型名、客户端配置或请求体。
CSV 导出说明
CSV 导出就是把当前列表按相同列导出,适合企业和团队做周报、成本分摊、异常复盘和成员用量对账。
导出后可使用 在线 CSV 查看器 打开预览。该工具支持拖拽或选择 CSV 文件,也可以粘贴 CSV 文本,适合快速检查列内容和失败原因。
| 导出表现 | 说明 |
|---|---|
| 分组行 | 类型 为 分组,用户 ID、用户名、令牌通常为空,表示该分组的整体汇总 |
| 令牌行 | 类型 为 令牌,会展示用户 ID、用户名和令牌名称,表示该分组下的成员或 Token 明细 |
| 金额格式 | 消耗 以控制台金额格式展示,例如 ¥905.48 |
| 百分比格式 | 成功率、缓存命中率、缓存请求占比会导出为百分比 |
| 数字格式 | 大数字可能带千分位分隔符,适合直接阅读或导入表格工具 |
| 时间格式 | 开始时间、最后请求会导出为本地时间,便于和问题发生时间对齐 |
| 失败原因 | 多个高频错误会合并展示,并在末尾标出出现次数;无错误时为空或 - |
排查流程
一、判断影响范围
先看 类型=分组 的汇总行。如果“成功率”接近正常水平,且“错误”很低,通常是偶发错误,可复制单条请求的 request_id 继续排查。
如果某个分组的“成功率”明显低于其他分组,或“错误”集中升高,优先按分组排查模型、Token、上游账号、套餐权限和平台资源状态。
企业或团队场景下,再看该分组下的 类型=令牌 明细行。如果只有某个用户或令牌异常,优先排查该成员的客户端配置、Token、模型名、请求体和并发策略。
二、再看 Top 错误原因
“失败原因”通常按出现次数展示。排查时先处理最高频错误,再看低频错误。高频错误能反映当前时间范围内的主要故障类型。
| 错误类型 | 常见日志关键词 | 初步归因 | 优先判断 |
|---|---|---|---|
| 频率限制 | Account RPM limit exceeded、Max 10/min、Max 5/min | 使用问题或上游限制 | 并发或每分钟请求数过高 |
| 日额度限制 | Account daily limit exceeded | 上游限制 | 上游账号今日额度已用尽 |
| 凭证冷却 | All credentials ... are cooling down | 上游限制 | 当前模型上游凭证均处于冷却期 |
| 请求体过大 | status_code=413、openai_error | 使用问题 | 上下文、文件、图片或工具结果过大 |
| 权限或认证 | 401、403、Invalid API key、pending admin approval | 使用问题或账号状态 | Token、套餐、分组或模型权限异常 |
| 无可用资源 | No available accounts、No available channel、auth_unavailable | 平台问题或配置问题 | 当前分组没有可用账号、通道或认证资源 |
| 上游异常 | 502、all upstreams failed、Upstream request failed | 上游问题 | 上游服务或中间网络异常 |
| 网关超时 | 504、521、522、524 | 上游问题或链路问题 | 上游连接、读取或响应超时 |
| 平台资源保护 | system disk overloaded、Service Unavailable | 平台问题 | 平台节点或上游资源暂不可用 |
| 图像接口格式 | gpt-image-2、prompt is required、multipart form | 使用问题 | 图像接口路径、提示词或上传格式错误 |
| 工具调用格式 | tool_use、tool_result、Invalid schema | 使用问题 | 客户端工具消息或 JSON Schema 不符合要求 |
三、按影响范围处理
| 现象 | 更可能的原因 | 建议处理 |
|---|---|---|
| 只有单个 Token 报错 | Token 配置、权限或本地请求格式问题 | 重新复制 Token,检查客户端配置和请求体 |
| 只有单个模型报错 | 模型权限、模型通道或上游模型资源问题 | 切换同类模型,确认当前套餐是否支持该模型 |
| 只有单个分组成功率低 | 分组资源池、套餐权限或上游账号问题 | 切换分组/模型,联系支持时提供分组名和时间范围 |
多个分组同时出现 502、504、521、522、524 | 上游或网络链路异常 | 稍后重试,减少长任务;持续出现时联系支持 |
多个请求都出现 413 | 请求体过大 | 缩短上下文,拆分文件,压缩图片或减少工具结果 |
多个请求都出现 429 | 请求频率过高、日额度用尽或凭证冷却 | 降低并发;根据日志区分 RPM、daily limit 和 cooling down |
四、结合消耗和缓存
| 现象 | 更可能的原因 | 建议处理 |
|---|---|---|
| “消耗”明显高于同组其他令牌 | 大上下文、长输出、高频调用或重复任务 | 结合请求数、平均耗时和错误日志,定位具体服务或成员 |
| “缓存命中率”高但“缓存请求占比”低 | 少量大请求命中缓存 | 检查是否只有固定任务在复用上下文 |
| “缓存请求占比”高但“平均缓存Tokens”低 | 很多请求命中缓存,但每次收益较小 | 检查上下文是否过短或缓存内容不稳定 |
| 单个令牌“平均耗时”明显偏高 | 客户端任务较重、上下文长、输出长或上游慢 | 对比该令牌的请求数、缓存、失败原因和单条日志 |
支持排查需要的信息
遇到简单问题时,建议先查看 错误日志说明 和 分组健康状态说明 自查。仍无法解决时,可以在 console/log 的错误日志详情中点击复制图标,一键复制排查内容。联系支持时,建议一次性提供以下信息给技术排查,减少来回确认:
- 用户 ID
- 时间范围:问题开始和最后出现的时间
- 分组名:
group - 模型名:请求使用的模型
- 状态码:例如
429、413、502、503 - 错误内容:
error_reasons.content - 请求 ID:单条日志或接口响应中的
request_id - 影响范围:单个 Token、单个模型、单个分组,还是多个分组同时异常
快速结论
401 / 403 多看权限,413 多看请求体,429 多看频率和额度,502 / 504 / 524 多看上游和长任务,503 多看资源是否暂不可用。